AI Coding 2026: How AI agentic development changed the way we deliver tech projects

Short summary:
In 2026, a Norwegian construction firm replaced two hours of manual renovation estimating with a thirty-minute AI-driven review — using six historical examples to teach the rules. Notes from LANARS in Oslo on what actually changed in software this year: coding agents as teammates, small senior teams shipping like big ones, and the constraint that is no longer engineering capacity. Two case studies (Lomundal, SelectAI), a practical 90-day plan for SMBs, and the risks that bite in production. About 13 minutes.
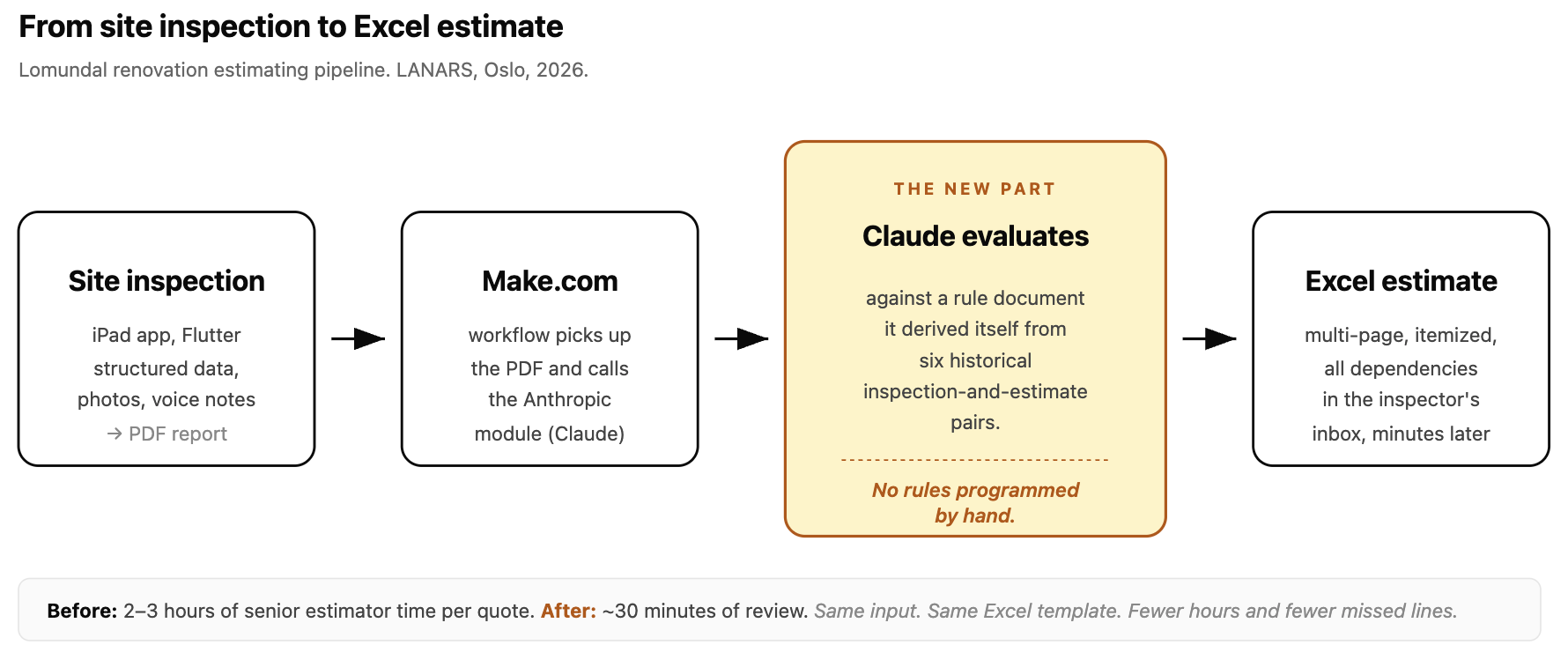
A Tuesday in Oslo. A Lomundal inspector closes the iPad app on a renovation he just walked through - three rooms, original wiring, a bathroom that has seen better decades. He hits "finish" and gets in his car. By the time he is back at the office, a multi-page Excel cost estimate is sitting in his inbox. Line items by trade, dependencies sorted, materials and hours and contingencies - the kind of itemized quote that used to take a senior estimator two or three hours. Nobody at Lomundal or LANARS programmed those rules. We gave Claude six historical pairs - inspection report and the estimate it had produced, six of them, that was all - and asked it to write the rules itself. The document Claude produced now lives inside a Make.com workflow. New inspection in, Excel out, before the inspector is home.
That is what changed in 2026. Not a slogan about computers thinking. A Norwegian construction company replaced the labour-intensive middle of its estimating process with a model that learned the company's own rules from six historical examples, and it is in production now, doing the work. The rest of this post is about what made that possible, what we are seeing across the projects we run from our office in Fornebu, and what we expect from the next twelve months.
A note on where we are coming from
LANARS started in Norway by 2018 as a small team partnering with companies in StartUpLab in Oslo. The bottleneck for those founders was almost always engineering capacity - the backlog was a list of "we'll get to it"s, every new feature meant a sprint, every sprint meant a hiring conversation. In 2026 the bottleneck has moved. Engineering capacity is cheap enough now that scope is no longer the constraint; judgement is. That is the entire premise of what follows.
The three shifts
Three things happened to software development at once, and they reinforce each other. The rest of the post works out the consequences.
- Coding agents became teammates. The IDE-side change everyone discusses, often poorly.
- Small senior teams ship like big ones. The team-economics change that has done more for our P&L than any of the others.
- AI is now expected inside the product itself. The customer-side change that is gradual but unmistakable.
Shift 1. Coding agents became teammates
In 2023, an engineer at LANARS would write a function name and let the model finish the line. In 2026, that same engineer opens an issue in Jira, hands it to Claude Code, and watches a working pull request appear twenty minutes later, with tests, with a description of the trade-offs the model considered, and with the kind of small refactors a careful senior engineer would have made along the way.
The engineer's job has not disappeared. It has moved, from typing characters to specifying intent, reviewing diffs, and orchestrating multiple parallel agent sessions at once. We have engineers running three or four Claude Code sessions in different worktrees simultaneously: one shipping a feature, one writing tests for last week's work, one debugging a flaky CI run, one auditing dependency upgrades. The output is still reviewed by a human. The generation is not.
We made Claude Code the engineering standard at LANARS at the start of 2026. Every engineer uses it every day. New engineers are onboarded on it within their first week. The productivity gap between agent-led and non-agent-led workflows is wide enough in 2026 that allowing it to be optional was, frankly, leaving money on the table. We made the call to standardise and we don't regret it.
Shift 2. Small senior teams ship like big ones
The second shift is quieter but, for us, more important. Through 2024 and 2025 we hired by discipline: backend, frontend, mobile, DevOps. We were good at this. We still are. But the cost of stepping outside your discipline has collapsed in 2026, and the engineers who can take that step are dramatically more valuable than the ones who can't.
The reason is simple. An engineer who understands what good architecture looks like - who can read a system, decide what should live where, and judge whether a proposed change fits the model - can now legitimately ship across the whole stack. The mechanical parts of working in an unfamiliar framework or runtime are exactly the bounded, well-specified tasks where agents excel.
So the bottleneck on "can this person ship across web, mobile, embedded, and infrastructure?" is no longer "do they know all four in equal depth?" It is "can they reason about the architecture well enough to direct an agent that handles the details?" The architectural-literacy bar has gone up. The stack-specific knowledge bar has gone down.
For us this means small senior teams ship enormous amounts of work. Six people on a project is plenty, when each of those six can credibly direct multiple agents through whatever stack the work demands. We feel the output of teams two or three times our size, and that is the ratio we hear most often from founders who have worked with us this year.
Shift 3. AI is now expected inside the product itself
The third shift is on the customer side, and the strongest version of the claim is overstated, so we will state it carefully. In 2023, AI was something you bolted onto an existing product as a feature flag. In 2026, customers - both consumers and B2B operators - notice when a product they are trying has a smart layer somewhere and an alternative they have just tried doesn't. Smart search. A conversational onboarding step. A workflow that drafts the email so the human just edits. An agent that does the boring middle of a task.
This is not a hard requirement in every category. We will not pretend it is. What we will say is that it shows up in client conversations more often than it did a year ago, and the direction of travel is clear. Shipping a SaaS without one of these in 2026 is increasingly a positioning choice that has to be defended, not a default that doesn't need to be.
The rest of this post is mostly cases and consequences of the three shifts above. We will keep referring back to them.
Inside the engine room
There is a kind of dishonesty in agency content about AI that we want to avoid - the framing of "we use AI to deliver projects" without specificity, the line every consultancy on Earth is writing this year. So here is what is actually true inside LANARS in 2026, with the parts we are confident about and the parts that are still in flux. Claude Code is mandatory. Every engineer at LANARS uses it every day, since the start of 2026, no opt-out. The biggest lift is at the start of new work. When we sit down to a brand new project, or a new feature inside an existing one, the time saved is not "a bit." It is several times faster than the same team would have moved in 2024. We bring up scaffolding, data models, API surfaces, the boring middle of UI, test harnesses, deploy configuration - all of it before lunch on day one. The remainder of the project is where human time goes, but time-to-meaningful-prototype has collapsed.
The lift is more even across disciplines than we expected. Backend, frontend, mobile, DevOps - all moved roughly in step. The constraint in each discipline was typing the boilerplate, not the hard part. The hard parts are still hard. They are just no longer surrounded by hours of mechanical work. Monitoring matters more, not less. When software gets cheaper to write, the cost of not knowing what is happening in production goes up, because the things you don't see get shipped faster too. We invested in observability - logs, traces, error tracking, AI-assisted production investigations - to keep up with the speed at which the code is changing. Architecture is the new gating skill. We hire seniors. We do not hire juniors in 2026, at least not yet, and that is a deliberate choice. The gating skill in an agent-led workflow is architectural literacy - the ability to direct, to review, to refuse bad output. That skill is not built by writing CRUD endpoints in your first year. It is built over a decade.
We have a longer version of this thinking on our AI Strategy 2026 page, including how we think about governance, the difference between vibe coding and AI-assisted engineering, and the senior-only operating model. The short version of all of it sits in the pull quote above.
Case study one. Lomundal: when six examples were enough
Lomundal is a Norwegian construction company based in Oslo, doing renovation projects across the region. Their estimators look at a flat or a house, decide what needs replacing, what can be patched, what is structural, what is cosmetic, and produce an itemized cost estimate. The estimate has to be detailed - multiple trades, dependencies between line items, materials, hours, contingencies - and it has to be defensible if a customer questions a line. The bottleneck was not the inspection. We had already built Lomundal a Flutter iPad app that handles the inspection itself: structured data capture on site, photos, voice notes, instant PDF generation. The bottleneck was the estimating phase that followed.
We started this project the way we would have started it in 2024 - by trying to write the rules out. We sat with senior estimators. We asked them how they decided what to include. We wrote things down. And we hit a wall fast. There were hundreds of line items. There were dependencies. There were "well, it depends on what else is in the room" judgements. There were exceptions. The rule set was too tangled to program by hand without a multi-year project, and Lomundal didn't need a multi-year project. This is where 2026 changes the answer. Instead of programming the rules, we gave Claude six historical inspection reports paired with the corresponding estimates Lomundal had produced. Six. We told it: figure out the rules. Write them down.
It did. The output was a long, structured rule document that read like the same logic Lomundal's estimators had been carrying in their heads, but explicit. The estimators read it, corrected the parts that were wrong, added the implicit constraints Claude had missed, and handed it back to us.
That document now lives inside the Make.com pipeline, called via the Anthropic module. A new inspection arrives as a PDF. Make hands the PDF to Claude with the rule document attached. Claude produces the line items. A small post-processor formats them into the company's Excel template. The estimator's job is no longer "build the estimate from scratch." It is "review the Excel, adjust where Claude was wrong, send it out." What used to be a two-to-three-hour task per estimate is now a roughly thirty-minute review pass. The pipeline is in early production - fewer than fifty estimates have run through it as of writing - but the time reduction has been consistent across the batch.
The other benefit is reliability. Manual estimating at this complexity is exactly the kind of work where a tired person at five in the afternoon misses a line, skips a dependency, or forgets to apply a markup. The Claude-derived pipeline produces the complete output every time. The estimator's review catches the rare case where the model misread the report; the model catches the cases the estimator would have missed.
The lesson from Lomundal goes well beyond construction. This is a pattern, not a one-off. Almost every SMB has some version of this lurking in their operation - a finance team that follows unwritten rules about how to categorise an invoice, an ops team that knows which orders to flag for review, a support team that knows when to escalate. The pattern is the same in each case: pair historical examples with their outcomes, ask Claude to write the rules, review and correct, then operate. The six-example detail should be the headline, not a footnote - the cost of trying this on a workflow inside your own business is far smaller than most operators assume. This is the part of "AI for SMBs" we think is most under-discussed in 2026. Everyone is talking about chatbots. The bigger near-term ROI for small operators is here - using AI as a tool to extract and then to apply the implicit logic the business already runs on.
Case study two. SelectAI: a Norwegian aquaculture startup, six months from concept to pilot
The other case study is a startup, not an SMB. It is the cleanest example we have of what AI-native development velocity actually looks like end to end. SelectAI is a Norwegian aquaculture startup. Sea lice are one of the biggest economic and welfare problems in the Norwegian salmon industry; the standard practice for measuring lice load is to net out fifteen to twenty fish per cage every week and count by hand. The sample size is small enough that an outbreak can be a week away before anyone sees it in a report. SelectAI's answer is a floating in-cage unit, the SelectAI 350, that captures every fish from three synchronised camera angles as the fish voluntarily swim through an analysis channel. A computer-vision model classifies each fish - lice categories matching Mattilsynet's own taxonomy, welfare indicators, juvenile lice that manual counts often miss. About a thousand fish per session instead of fifteen.
LANARS built the firmware and the software in partnership with AI Experts, a Grimstad-area AI firm. I sit on the SelectAI board, so I will keep the brag list short - what is worth noticing here is the timeline. From concept to a working hardware unit, validated software, an annotation pipeline used by biologists, and pilots on real Norwegian farms: six months. The team is three people. In 2024 a project with this scope would have been a year and a half with a team twice the size. The interesting design choice is one we want to spend a moment on, because it captures shift 2 (small senior teams) and shift 3 (AI inside the product) at once: the hardware was designed around the model, not the other way around.
The tri-angle camera layout exists because the model needs three synchronised views to avoid double-counting the same salmon across its left and right flanks. We built the rig around what the model required - patent pending, by the way. That is a small thing on the surface but a large one underneath: in 2024 we would have built the obvious single-camera rig and accepted the data quality penalty as a fact of physics. In 2026, the model gets veto power on the hardware spec because the model is the product. The validation cycle is fast for the same reason every other 2026 project is fast: the cost of building one more piece of tooling is small. When the SelectAI team needs a custom view of how the model performed on a specific cage, that view ships the same week, not in a quarter's planning. The annotation tool itself, used by biologists across multiple Norwegian sites, was built and revised on this same cycle. We will mention three traction points and stop, because the lesson is in the velocity, not the trophy case: fifteen thousand fish analysed to date, field validation at Varde Fiskeoppdrett and Lerøy under real winter conditions, and backing from Innovasjon Norge. The headline goal - Mattilsynet approval as an automated lice-counting system, which would replace manual counts at regulator-grade - is targeted for the end of 2026. The version of this story we want operators and founders to read is: small team, short cycle, AI in the build process and in the product simultaneously, hardware designed around the model, field validation inside year one. None of that was routine in 2024. All of it is routine in 2026.

What this means for founders
The biggest change for a startup founder in 2026 is the cost of trying. The "test the idea" stage of a startup used to cost six months and most of a seed round. In many categories it now costs a fortnight and a sliver of one. The patterns that took us a year to build for StartUpLab teams in 2018 are weekend exercises now. That has produced two cohorts of founders at once, and it is worth naming both because they will define the noise floor of the startup market for the next two years.
One cohort is the wannabe-vibecoder - solo founders with caffeine and a coding agent, shipping prototypes that don't solve a real problem. Most won't last a quarter. Real noise in the market because of this: investors see more pitches, hiring is louder, attention is harder to get. The other cohort is the founder for whom real value reaches market faster. These are people who had the right problem and were always going to build the right thing - they just had to wait six months for an MVP. Now they wait six weeks. Feedback loop starts earlier. The good ones look like SelectAI: real partners, real money, real validation inside year one.
For founders raising in 2026, here is a concrete framing we expect investors to converge on within the next six months. A startup whose MVP took more than eight weeks should be ready to explain why - either the scope was unusually deep (regulated industry, novel hardware, real ML), or something was off in how the team approached the build. The benchmark has tightened, and it will keep tightening. The strategic implication is uncomfortable. The bar for being noticed is higher because the noise is louder; the bar for being real is lower because shipping is cheaper. Distribution, taste, and the ability to talk to customers - the parts AI doesn't do - are the actual constraint now. Engineering capacity isn't.
What this means for operators
For a small or medium-sized business running an existing operation, the answer is different, and arguably more immediately profitable. The Lomundal story is the template. Find one repetitive, well-defined operation inside your business - usually one bottlenecked on a senior person's time. Estimating, classification, drafting, triaging, reporting, summarising. Pick the one with the cleanest inputs and outputs. Get a Make.com or equivalent workflow running. Hardcode the prompt. Wire one customer or one internal team to it. Measure for a month. We see two failure modes consistently.
The first is picking the flashy use case first. The flashy use case is usually customer-facing and high-stakes. It is the wrong place to start. Start with the boring internal workflow that nobody is excited about. A flawed customer-facing AI feature embarrasses you in front of users. A flawed internal workflow only embarrasses you in front of yourself, which is the better classroom.
The second is not measuring. AI features not instrumented from day one rot quietly. Model drift, prompt regressions, edge cases that arrive once a month - these are not visible without observability. The same discipline that matters for any production service matters for AI workflows, and arguably more, because the failure modes are stranger and less mechanical.
On ROI, an honest observation rather than a promise. Across the SMB engagements we have run in 2025 and 2026 that look like Lomundal in shape - bounded internal workflow, narrow inputs, narrow outputs - we typically see operation-time reductions in the range of five to ten times, and payback on the build inside one to three months. The variance is wide. The projects with the cleanest historical data and the most patient review cycle sit at the high end of the range; the projects that try to do too much at once sit at the low end. Treat those numbers as a sighting frame, not a quote.
The 2026 stack (CTO note)
If you are a CTO choosing technology in 2026, here is the short opinionated version. CEOs without a CTO in the room can skip ahead without missing anything important. For the web side, the principle is to pick a framework with first-class support for streaming and partial rendering, deployed on a platform that gives full Node.js (not edge-only), long function timeouts, and instance reuse for AI workloads. These are not exotic requirements in 2026; they are table stakes. For model access, the highest-leverage decision is to route through a model gateway rather than directly to a single provider. Provider strings make switching a one-line change. Fallback routing handles provider hiccups. Zero data retention should be the default. Unified billing means fewer invoices to chase. The gateway is the part of any AI stack that has paid back fastest in our projects, by a wide margin.
For storage, prefer managed Postgres, managed Redis for hot-path caches, and managed object storage for uploads, all provisioned through a single marketplace so environment variables land where they should without manual plumbing. For auth, a managed identity service with middleware-based session checks. For mobile, a cross-platform framework that the same agent-driven engineering pattern fits naturally; we have used Flutter on both Lomundal and SelectAI for that reason. This stack is opinionated because the opinions earn the time back. A team that picks something else can absolutely succeed - but they will spend founder hours on infrastructure decisions nobody remembers two years later. We would rather spend those hours on the product.

Where things break
The risks in 2026 are not the risks people worried about in 2023. "Will AI replace developers" is not a 2026 conversation. The real risks are quieter, and they are about discipline more than technology. Listed roughly in order of how often they bite Norwegian operators we work with.
Data governance. For Norwegian companies serving regulated industries - healthcare, finance, anything touching the GDPR landscape - the question of where data goes when sent to an LLM has to be answered before the first prototype ships. The two practical defaults: route through a gateway with zero data retention, and pick providers with explicit DPAs and regional deployment options. We have had this conversation with several Norwegian SMBs and it is rarely as complicated as their legal team initially fears, but it has to be answered explicitly, not implicitly. The risk is not the regulator catching you; the risk is shipping a feature you later have to rip out because it cannot be defended.
Hallucinations in production AI features. This is the risk most teams underestimate in their second AI feature, after the first one worked. Production models will, occasionally, produce a confident answer that is wrong. The pattern that contains this is the same one that contains every other reliability risk: bound the surface area of what the model is allowed to say, ground its answers in retrievable data where possible, validate outputs against a schema before they reach a user, and instrument so that you see the failure modes early. Hallucinations are not a research-stage problem; they are an engineering problem with known mitigations and they should be a checklist item, not a hope.
Code without comprehension. The most common failure mode in teams that adopt agents without discipline is shipping code they do not fully understand. Compiles, tests pass on the surface, and six weeks later something subtle breaks in production with nobody on the team able to read the broken thing fast enough to fix it. The mitigation is the senior-only model we wrote about above - reviewers who can keep up with the rate of generated code without losing comprehension. Speed without comprehension is debt with a deadline.
Provider lock-in as a margin issue. In 2023 this was an annoyance. In 2026, with weekly model releases and order-of-magnitude pricing differences between capability tiers, it is a margin issue. Architect every project so provider and model are configuration values, not code. The cost of doing this is small; the cost of not doing it accumulates monthly.
The new on-call. AI-generated code that breaks in production needs a human who can read the failure, the diff, the trace, and the model's reasoning, and decide what to roll back. The on-call engineer's job has shifted from "fix it" toward "judge it." The traditional senior-engineer skill set has gotten more valuable, not less.
A practical 90-day plan
If you run an SMB and want to test what AI can do for your operation, here is the shape of the first ninety days that works most consistently for us.
Days 1 to 14. Pick one workflow. The single most repetitive, well-defined, low-stakes workflow inside the business. Drafting a reply, summarising a record, tagging an upload, generating an estimate from a report. Avoid the customer-facing one. Avoid the one that "would be amazing if it worked." Start with the boring one whose inputs and outputs you can describe in a paragraph.
Days 15 to 30. Ship the smallest possible version. Make.com or equivalent. Hardcode the prompt. One internal user. Instrument every input, every output, every model call. Do not skip the instrumentation. It is the whole game.
Days 31 to 60. Add the data layer. If the workflow benefits from your historical data - and it almost always does, as Lomundal shows - feed Claude historical examples and let it derive the rules. Review with the domain expert. Correct the obvious mistakes. Hand them back to the pipeline.
Days 61 to 90. Industrialise. Version the prompt. Add a fallback model. Move the rule document into version control. Add a small evaluation harness that runs against a frozen set of historical examples whenever prompts or rules change. Document what the workflow does and what it doesn't.
By day ninety the workflow is doing real work, the infrastructure is there to add the next ten workflows without rebuilding, and the team has internalised the pattern.
Frequently asked questions
- What does "AI-native development" actually mean in 2026?
Two things at once. The engineering workflow uses AI tools - coding agents, AI code review, AI-driven testing - as the daily standard, not an experiment. The product itself ships with AI as a primary capability - chat, retrieval-augmented search, autonomous workflows - rather than as a bolted-on add-on. - How long does it take to build an MVP in 2026 compared with 2024?
Two to five times faster in our experience, depending on scope. SelectAI shipped a working hardware-plus-software product in six months with a team of three - a project that would have been a year and a half in 2024 with a team double the size. For pure software MVPs, three to eight weeks is realistic for what used to take three to six months. Remaining time goes to product judgement, customer conversations, and design - not engineering./ - Can AI build my MVP without engineers?
For a true production MVP - with auth, payments, data ownership, a path to scale - no. AI tools accelerate engineering, but a human is needed to make architectural calls, review changes, own security, and judge product trade-offs. A realistic 2026 number is one engineer (or one technical founder) doing the work of a 2023 team of three to five. - Is AI-generated code safe to ship to production?
With a normal engineering workflow - review, tests, CI, observability, on-call - yes. AI-generated code is shipped to production every day at companies of every size in 2026, including ours. The pattern that fails is "ship without review." The pattern that works is the one that worked before AI: small diffs, tests, review, observability. - Which model should I choose for my product?
Route through a gateway. Pick a frontier model for quality-critical paths, a smaller faster cheaper model for high-volume low-stakes paths. The specific winner on quality and price changes monthly; the architectural answer - model as a configuration value, not a code change - does not. - Do we need to train our own model?
Almost never. Across the projects we have shipped or audited in 2025 and 2026, fewer than one in twenty have benefited from training a model from scratch. The rest get more leverage from frontier models combined with good retrieval, good prompts, and good UX. The exceptions are domain-specific verticals operating at scale with proprietary data - SelectAI's computer-vision model is one, because off-the-shelf models do not know what a Norwegian sea louse looks like. - What is the difference between SEO and AEO?
SEO (search engine optimisation) ranks content in classical search engine results. AEO (answer engine optimisation) gets content cited by AI answer engines - Perplexity, ChatGPT, Claude, Google AI Overviews - when they respond to user questions. AEO favours clear factual statements, explicit question-and-answer blocks, well-structured headings, and entity-rich content a model can extract and quote. - Where in our product should we start with AI?
With the boring internal workflow nobody is excited about. The flashy customer-facing feature is high-stakes; a flawed AI feature shown to customers damages trust. A flawed internal workflow only embarrasses you in front of yourself, which is the better classroom.
Engineering capacity used to be the constraint. It isn't anymore. The constraint is whatever was always harder - knowing what to build.
Have a look at other our articles

04.02.2026
How AI is Changing Development: From Skepticism to Real ResultsA year ago, if someone had asked me: "Can you build a proper application with AI?" I would have categorically answered "no." Today, my answer has changed to "yes," but with important caveats. Over this past year, we've gone from experiments to real AI implementation in our development process, and the results have been surprising.Read more
04.07.2025
How We Do Business Analysis at LANARS – And Why It MattersBehind every successful tech product lies a clear understanding of its purpose, audience, and functionality. That clarity doesn’t happen by accident — it’s the result of a structured, thoughtful Business Analysis process.Read more
07.05.2025
Mastering the CTO Role in Startups: What It Really TakesWhat does it actually mean to be a CTO at a startup?Read more